

三、二级索引
三、二级索引
聚簇索引只能在搜索条件是主键值时才能发挥作用,因为B+树中的数据都是按照主键进行排序的。那如果我们想以别的列作为搜索条件该咋办呢?难道只能从头到尾沿着链表依次遍历记录么?不,我们可以多建几棵B+树,不同的B+树中的数据采用不同的排序规则。比方说我们用c2列的大小作为数据页、页中记录的排序规则,再建一棵B+树,效果如下图所示:
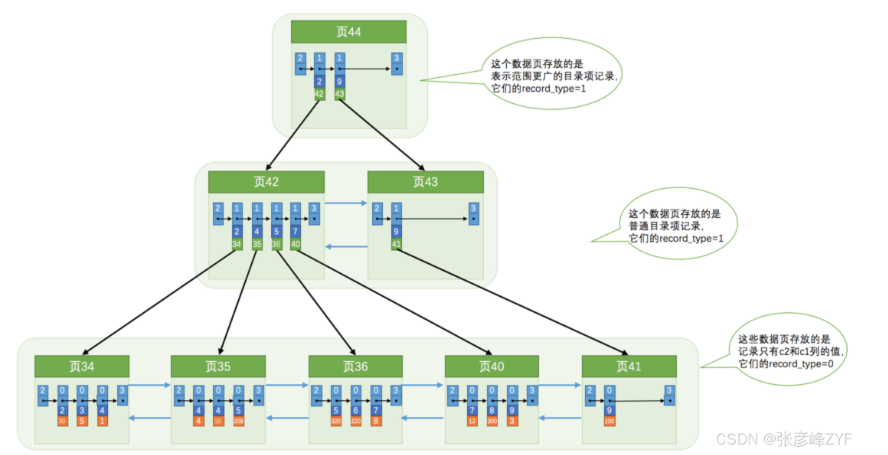
在InnoDB存储引擎中,除了聚簇索引(Clustered Index),我们还可以使用二级索引(Secondary Index)来提高非主键列上的查询性能。二级索引是一种基于非主键列的B+树结构,用于快速定位数据记录。
(一)二级索引的特点
基于非主键列排序
二级索引的B+树结构基于指定的非主键列进行排序,这包括以下几个方面:
页内记录排序:在每个页内,记录按照指定列(例如c2列)的大小顺序排成一个单向链表。
页之间的排序:存放用户记录的页按照页内记录的指定列顺序排成一个双向链表。这种结构便于快速范围查询和顺序扫描。
目录项页的排序:存放目录项记录的页根据页内目录项记录的指定列顺序排成一个双向链表,不同层次的页同样遵循这种排序规则。
叶子节点存储部分数据
与聚簇索引不同,二级索引的叶子节点存储的是索引列和主键列的值,而不是完整的用户记录。这种设计减少了存储空间的占用,但在查询过程中需要进行回表操作以获取完整的用户记录。
(二)二级索引的工作流程
假设我们创建了一个基于c2列的二级索引,并通过c2列的值查找某些记录,以查找c2列的值为4的记录为例,查找过程如下::
确定目录项记录页
从根页面开始,根据c2列的值4定位到目录项记录所在的页,通过页44快速定位到目录项记录所在的页为页42(因为2 < 4 < 9)。
通过目录项记录页确定用户记录真实所在的页
在页42中,根据c2列的值确定实际存储用户记录的页。由于c2列没有唯一性约束,值为4的记录可能分布在多个数据页中。最终确定实际存储用户记录的页在页34和页35中(因为2 < 4 ≤ 4)。
在真实存储用户记录的页中定位到具体的记录
在页34和页35中定位到具体的记录,但二级索引的叶子节点中仅存储c2列和主键列c1的值。
回表操作
根据主键值到聚簇索引中查找完整的用户记录。这个过程称为回表操作,即从二级索引定位到主键,再通过主键在聚簇索引中查找完整记录。
(三)二级索引的优缺点
二级索引的优点 二级索引的缺点
提高查询效率:基于非主键列的查询可以利用二级索引快速定位数据,减少全表扫描的开销。 回表操作:查询完整记录时需要回表操作,增加了一次I/O开销。
灵活性:可以为多个列创建二级索引,提升多种查询条件下的性能。 占用空间:虽然叶子节点不存储完整记录,但仍会占用额外的存储空间。
二级索引通过基于非主键列排序和存储索引列与主键列的值,为非主键列的查询提供了高效的解决方案。然而,由于叶子节点仅存储部分数据,查询完整记录时需要回表操作。因此,合理使用和配置二级索引,对于提升数据库查询性能至关重要。 具体优化可见:MySQL索引性能优化分析。原文链接:https://blog.csdn.net/xiaofeng10330111/article/details/142446131

赶快来坐沙发