标签: ProxySQL

MySQL中间件之ProxySQL(15):ProxySQL代理MySQL组复制
1.ProxySQL+组复制前言
在以前的ProxySQL版本中,要支持MySQL组复制(MGR,MySQL Group Replication)需要借助第三方脚本对组复制做健康检查并自动调整配置,但是……
MySQL中间件之ProxySQL(14):ProxySQL+PXC
1.ProxySQL+PXC
本文演示ProxySQL代理PXC(Percona XtraDB Cluster)的方法,不涉及原理,纯配置过程,所以如有不懂之处,请先掌握相关理论。
ProxySQL要代理PXC……

MySQL中间件之ProxySQL(13):ProxySQL集群
ProxySQL有原生的集群功能,但是这个原生的集群功能还正在试验阶段。本文会详细介绍这个原生集群的实现细节。
1.ProxySQL部署在哪
在拓扑结构中,ProxySQL部署……
MySQL中间件之ProxySQL(12):禁止多路路由
1.multiplexing
multiplexing,作用是将语句分多路路由。开启了multiplexing开关,读/写分离、按规则路由才能进行。但有时候,有些语句要求路由到同一个主机组……
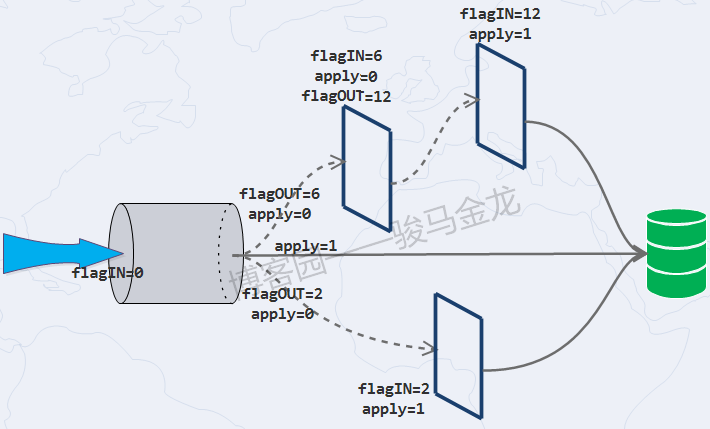
MySQL中间件之ProxySQL(11):链式规则( flagIN 和 flagOUT )
1.理解链式规则
在mysql_query_rules表中,有两个特殊字段"flagIN"和"flagOUT",它们分别用来定义规则的入口和出口,从而实现链式规则(chains of rules)。
链……
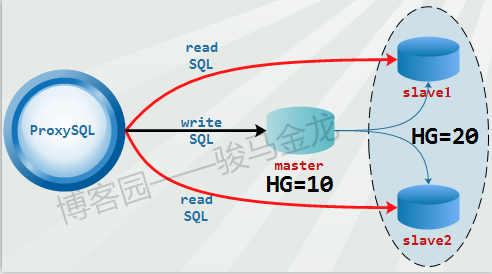
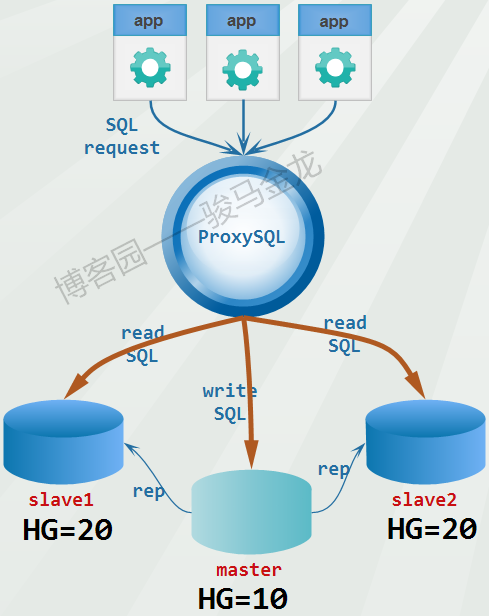
MySQL中间件之ProxySQL(10):读写分离方法论
1.不同类型的读写分离
数据库中间件最基本的功能就是实现读写分离,ProxySQL当然也支持。而且ProxySQL支持的路由规则非常灵活,不仅可以实现最简单的读写分离……
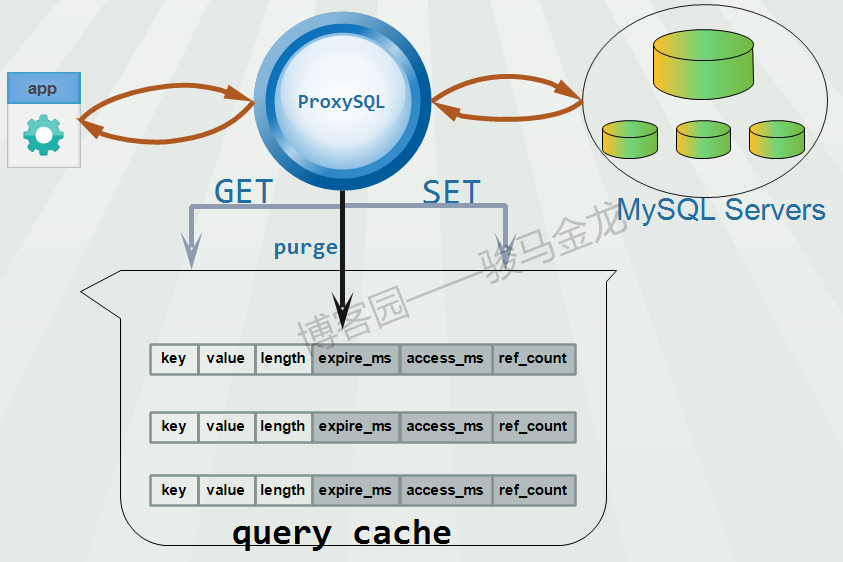
MySQL中间件之ProxySQL(9):ProxySQL的查询缓存功能
ProxySQL支持查询缓存的功能,可以将后端返回的结果集缓存在自己的内存中,在某查询的缓存条目被清理(例如过期)之前,前端再发起同样的查询语句,将直接从缓存……
MySQL中间件之ProxySQL(8):SQL语句的重写规则
1.为什么要重写SQL语句
ProxySQL在收到前端发送来的SQL语句后,可以根据已定制的规则去匹配它,匹配到了还可以去重写这个语句,然后再路由到后端去。
什么时候……
MySQL中间件之ProxySQL(7):详述ProxySQL的路由规则
1.关于ProxySQL路由的简述
当ProxySQL收到前端app发送的SQL语句后,它需要将这个SQL语句(或者重写后的SQL语句)发送给后端的MySQL Server,然后收到SQL语句的My……
MySQL中间件之ProxySQL(6):管理后端节点
1.配置后端节点前的说明
为了让ProxySQL能够找到后端的MySQL节点,需要将后端的MySQL Server加入到ProxySQL中。ProxySQL的一切配置行为都是在修改main库中的对……