标签: Atlas 500
Atlas 500 无法登录ftp
问题描述
Xshell 能连接到Atlas 500命令行 , ftp 无法连接。 端口,IP都已检查无问题
解决方案
需要登录命令行执行 sftp enable 命令
免责声明:本……

Atlas 500 端口2ping 不通
问题描述
Atlas 500 端口2ping 不通,客户将Atlas 500的两个网口设置成一个网段IP后,只有一个网口能通
处理过程
1、Atlas 500的两个网口需要配置不……
atlas 500跳过ies
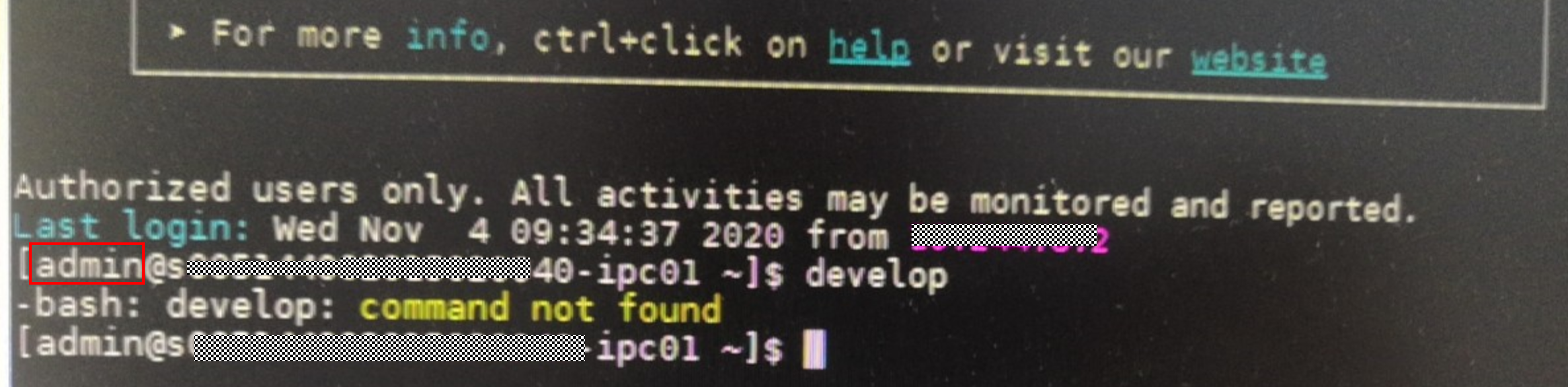
问题描述
正常情况下,Atlas500 ssh 的登录,是通过admin登录到IES,然后再通过develop 登录到开发者模式。
取消省界某局点客户,通过admin登录atlas500 的……

Atlas 500 硬盘无法识别
问题描述
更新了费率后,存储设备丢失,mcu电压检测异常
处理过程
日志查看无硬盘信息
日志记录有电源跌落告警
根因
电源线接触端子磨损导致电压……

Atlas 500 修改密码提示:passwd: Authentication token manipulation error
问题描述
Atlas 500系统下修改root密码时提示:passwd: Authentication token manipulation error
告警信息
处理过程
1.执行mount检查根分区是否……

Atlas 500 异常重启现象
问题描述
多台Atlas 500智能小站发生异常重启现象,影响现场业务运行。
处理过程
一线人员反馈现场3台设备出现异常重启现象,收集日志后,首先通过MCU日……