标签: 节点

CNA节点管理域CPU占用率超过阈值
问题描述
CNA节点管理域CPU占用率超过阈值告警,该节点只有2个业务虚拟机,迁移走后,管理域CPU占用率仍然没有得到释放。
告警信息
CNA节点管理域CPU占用率……
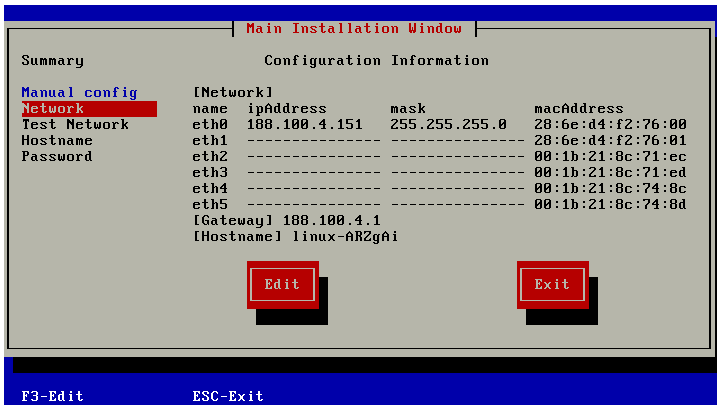
FusionCompute安装指导中PXE方式批量安装CNA节点--增强版
问题描述
当CNA节点的数量很大时,根据《FusionCompute_V100R003C10产品文档》通过PXE方式批量安装主机的过程依旧十分繁琐,需要登陆每台主机配置其信息,包……
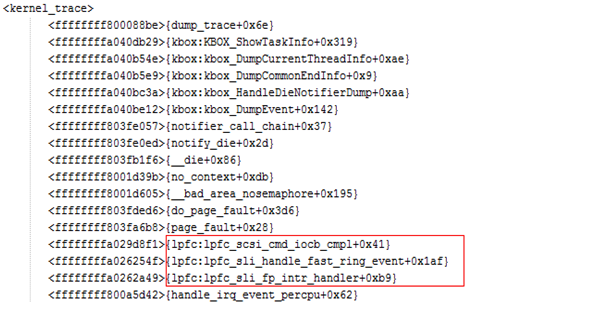
FusionCompute产品CNA节点重启问题
问题描述
某服务器虚拟化局点采用RH5885服务器作为CNA节点,两台CNA节点发生重启。
告警信息
无
处理过程
分别收集两台CNA的message日志分析,message日……

MySQL中间件之ProxySQL(6):管理后端节点
1.配置后端节点前的说明
为了让ProxySQL能够找到后端的MySQL节点,需要将后端的MySQL Server加入到ProxySQL中。ProxySQL的一切配置行为都是在修改main库中的对……