标签: 异常

禁用FC接口账号导致FA调用虚拟机异常
问题描述
客户反馈通过FA,执行虚拟机的关机操作失败及在FA上监控不到虚拟机的硬件信息。如图:
告警信息
FA告警FusionCompute服务器异常,如图:
处理……

虚拟化平台物理交换机VLAN配置错误导致FusionCompute网络通信异常
问题描述
虚拟化平台搭建完成后,在FusionCompute上部署业务虚拟机,为其配置IP及网关地址,测试网络时无法ping通网关地址。
告警信息
无
处理过程
1、在……
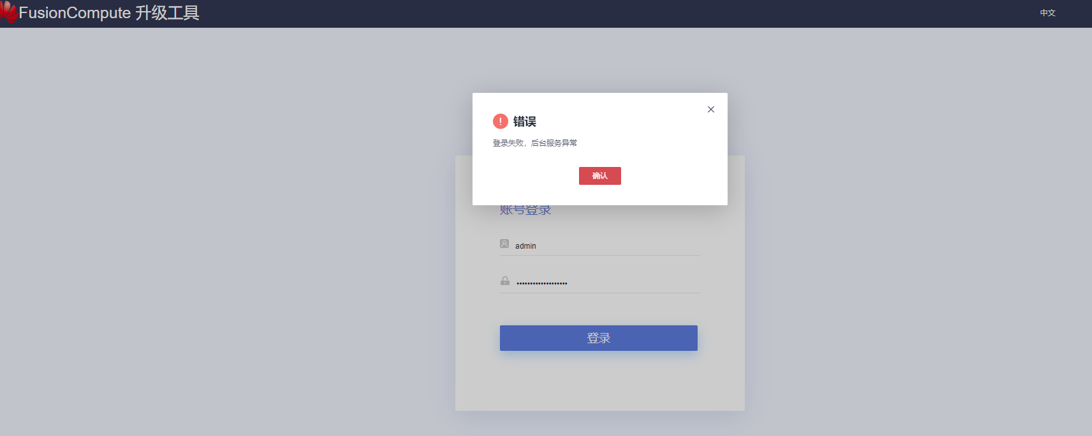
FusionCompute 登录升级工具显示后台服务异常
问题描述
工程师对FusionCompute进行升级,登录升级工具显示后台服务异常
告警信息
处理过程
先执行下stop.bat停止服务,再到pasql目录下……
iBMC硬盘告警异常问题解决案例
问题描述
客户在系统下电的情况下将配置在RAID组里硬盘拔出以后,在上电以后将硬盘插入,在整个过程中iBMC都没有告警。
告警信息
客户在系统下电的情况下将配……
Atlas 500 异常重启现象
问题描述
多台Atlas 500智能小站发生异常重启现象,影响现场业务运行。
处理过程
一线人员反馈现场3台设备出现异常重启现象,收集日志后,首先通过MCU日……