分类: 中间件

卸载网络适配器驱动对电脑系统有影响吗?
一、直接影响(必然发生)
网络功能完全中断
卸载后,电脑会失去与网络的连接能力,表现为:
Wi-Fi 列表消失(无线网卡驱动卸载);
以太网显示 “未识别的……

网络IP冲突怎么办?!这两招帮你一劳永逸
IP冲突看似简单,但若处理不当,可能反复发生,甚至引发ARP风暴。
今天给大家带来两招组合拳:
✅ 第一招:快速定位冲突源(精准到端口)
✅ 第二招:根治冲突……
在Spring Boot中使用RocketMQ事务消息进行消息的发送和接收的代码示例(极简可运行代码示例)
以下是 Spring Boot + RocketMQ 事务消息 的极简可运行代码示例,仅保留核心逻辑,剔除所有冗余代码,可直接复制运行。
一、环境准备
本地启动 RocketMQ(Nam……
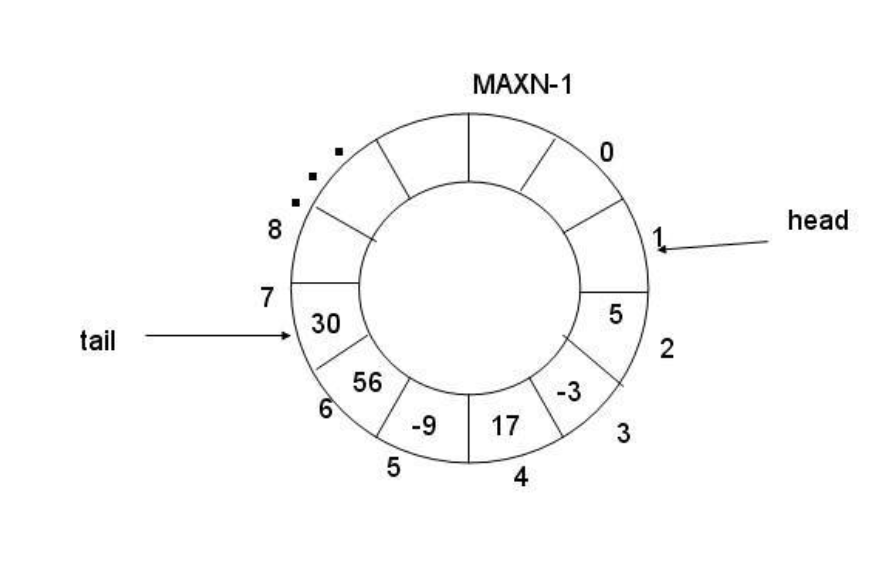
《从内核视角看 Linux:环形缓冲区 + 线程池的生产消费模型实现》
【一】环形生产消费模型介绍
“环形”生产消费模型:队列采⽤数组模拟,⽤模运算来模拟环状特性,例如:
特点:
(1)缓存大小初始后是固定的
(2)也符合数据“……
如何在设备管理器中卸载网络适配器驱动程序?
一、打开设备管理器(4 种快捷方式)
操作方式
适用系统
步骤
Win+X 菜单
Win10/11
按 Win+X → 选择「设备管理器」
搜索栏
Win10/11
点击任务栏搜……

VLAN划分后依然互通?这些常见“误配置”是罪魁祸首
你明明建了 VLAN10、VLAN20,把不同部门的设备分别放进去,还特意做了接口隔离。结果对方还能 ping,你傻眼了,客户也纳闷。
别慌,这事儿不一定是设备坏了……
在Spring Boot中使用RocketMQ事务消息进行消息的发送和接收的代码示例(核心配置)
以下是 Spring Boot 中使用 RocketMQ 事务消息的核心配置 + 极简可运行代码示例,聚焦关键配置和核心逻辑,剔除冗余代码,便于快速集成到项目中。
一、核心依……
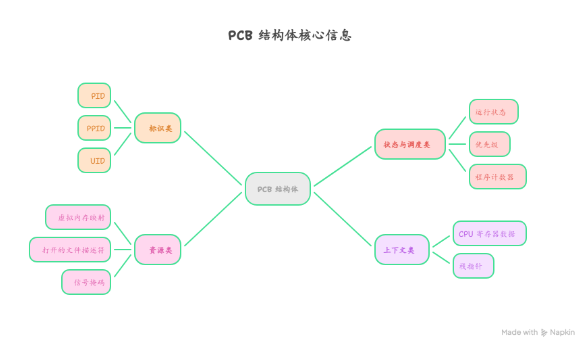
Linux 进程深度解析(一):从内核视角看懂进程的本质
在 Linux 系统中,我们每天都在和进程打交道 —— 执行 ls查看文件、用 top监控系统、启动应用程序,这些背后都是进程在工作。但你真的懂进程吗?课本说 “进程是……
如何重置网络适配器驱动程序?
一、快速重置(优先尝试)
禁用再启用适配器(修复临时故障)
右键任务栏网络图标 → 打开 “网络和 Internet 设置”
点击 “更改适配器设置” → 右键当前网卡(……
核心交换机的六个基础知识
01 背板带宽
背板带宽是指核心交换机内部数据传输的带宽,决定了交换机的最大吞吐能力。背板带宽直接影响了交换机处理和转发数据的能力。
01 重要性
高吞吐……