
在大型网络部署中,批量配置VLAN 是网工必须掌握的技能。如果还靠Console线一台台配置,不仅效率低下,还容易出错。 今天就来讲讲4种高效批量配置VLAN的方法,从脚本到自动化工具,帮你把原本需要一整天的工作,压缩到10分钟内完成。 方法1:使用Python脚本 + SSH(适合中小规模
 2026-02-09
2026-02-09

1. 动态修改 Tomcat maxThreads 后,为什么线程数还是上不去? 常见原因: Tomcat 线程池已经扩容,但压测不够大,没触发到上限 压测工具连接数 / 并发数不够 接口内部有锁、慢 SQL、外部调用阻塞,线程没真正并发跑 你改的不是当前在用的
 2026-02-06
2026-02-06

01 先搞清角色:Access 和 Trunk 是干啥的? Access 端口:接终端的“翻译官” 特点: 只属于一个VLAN(缺省VLAN) 对外发送帧时剥除Tag 接收无Tag帧时,打上PVID的Tag 典型连接:PC、打印机、IP电话 Tr
2026-02-06
一、先搞懂:Shell 的本质是 “命令管家” 在写代码前,我们先回归本质:Shell 是一个 “命令管家”—— 它的核心工作是 “接收用户命令→解析命令→调度资源执行命令→反馈结果”,具体流程可拆解为一个无限循环: 展示提示符:打印[用户名@主机名 工作目录]$,告诉用户 “可以输入命令了
 2026-02-05
2026-02-05
想要在 Nginx 中实现动态请求过滤规则(如封禁 IP、拦截路径、限制请求方法 / 频率等),核心思路是「配置解耦 + 热加载 + 动态推送」—— 将过滤规则从 Nginx 主配置中分离,通过外部配置文件 / 配置中心管理规则,修改后无需重启 Nginx,仅需热加载即可生效。以下是 4 种主流实现
2026-02-05

01 阶段一:部署前准备(70%的故障源于此) 01 明确网络规划 ✅ VLAN规划表: ✅ IP地址分配表: ✅ 端口命名规则: 1F-PC-01:1楼PC接入口 UPLINK-TO-CORE:上联口 02 检查硬件与环境
2026-02-05
除了 Tomcat 原生 Valve 之外,还有哪些方式能在 Spring Boot 中实现动态请求过滤规则(如封禁 IP、拦截接口、限流等),核心思路是从「应用层、网关层、容器层」三个维度出发,覆盖不同粒度的过滤需求。以下是 6 种主流方案,包含适用场景、实现步骤、优缺点对比,方便你根据业务场景选
2026-02-04
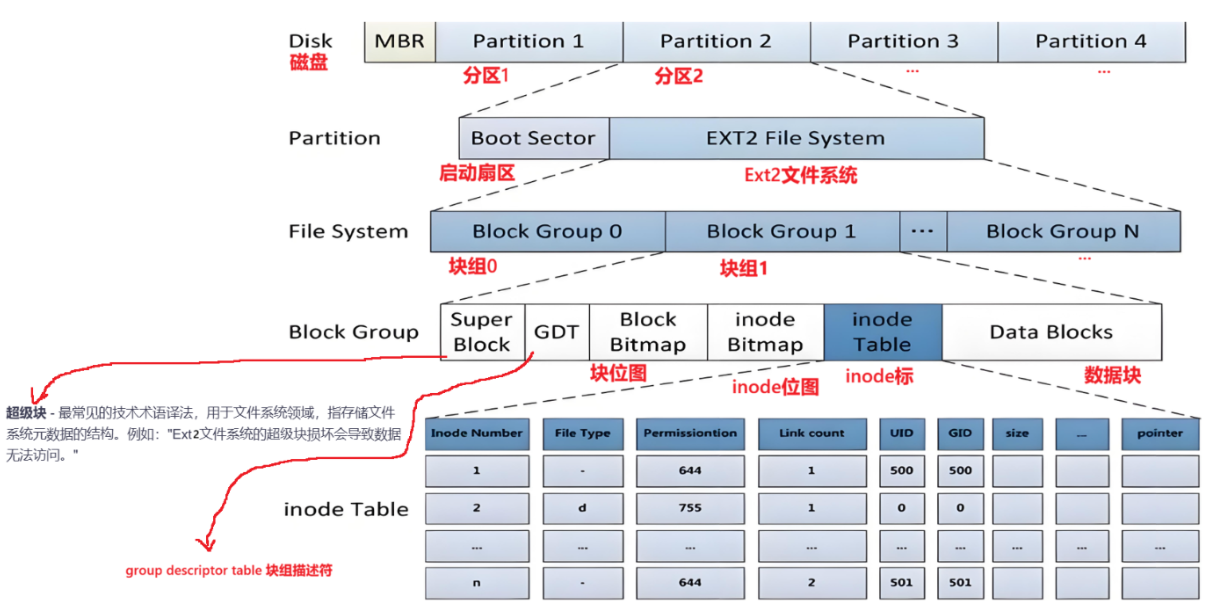
前言 在上一节中,我们留下了两个未解之谜: 问题一:块是如何在分区上排布的?我们该如何高效地找到目标块? 问题二:inode又存放在分区的什么位置? 其实,这两个问题的答案都指向同一个核心概念——文件系统。 还记得我们在 inode 结构定义中看到的 ext2_inode 吗?这个
2026-02-04
一、什么是端口闪断? 端口闪断 指交换机端口在短时间内反复出现 UP → DOWN → UP 的状态变化。 在日志中表现为: %LINK-3-UPDOWN: Interface GigabitEthernet0/0/5, changed state to down%LINK-5-UPDOW
2026-02-04
想要基于 Tomcat 原生的 Valve 实现动态请求过滤规则(比如封禁 IP、拦截特定路径、限制请求方法等),核心步骤是:「自定义 Valve 实现过滤逻辑」→「将 Valve 注册到 Tomcat 容器」→「提供接口动态更新过滤规则」→「验证规则生效」。以下是分步骤、可落地的完整实现,包含代码
2026-02-03