
在网络排障中,最让人困惑的场景之一就是: “两台电脑都在192.168.1.0/24网段,IP配置正确,网线也通,但就是ping不通!” 遇到这种情况,很多工程师第一反应是检查IP地址、子网掩码、物理链路…… 但当这些都正常时,问题很可能出在数据链路层——也就是 MAC地址 和 ARP协议
 2026-02-14
2026-02-14

想要在独立 Tomcat 中实现「配置热部署」,核心目标是修改配置后无需重启 Tomcat 进程,仅通过「配置重载、应用热加载、缓存刷新」等方式让新配置生效,且不中断现有业务请求。以下是分场景的完整方案,覆盖 Tomcat 核心配置、应用配置、业务配置三类场景,适配生产环境的热更新需求。 核心
 2026-02-13
2026-02-13
Linux 线程是系统编程的核心概念之一,作为轻量级执行单元,它在提高程序并发性能、优化资源利用率方面发挥着关键作用。本文将从底层原理、核心 API、同步机制、高级特性四个维度,结合代码示例和底层实现细节,为你系统讲解 Linux 线程知识。 线程知识点总览: 知识模块 核心内容 底层关键点
 2026-02-13
2026-02-13
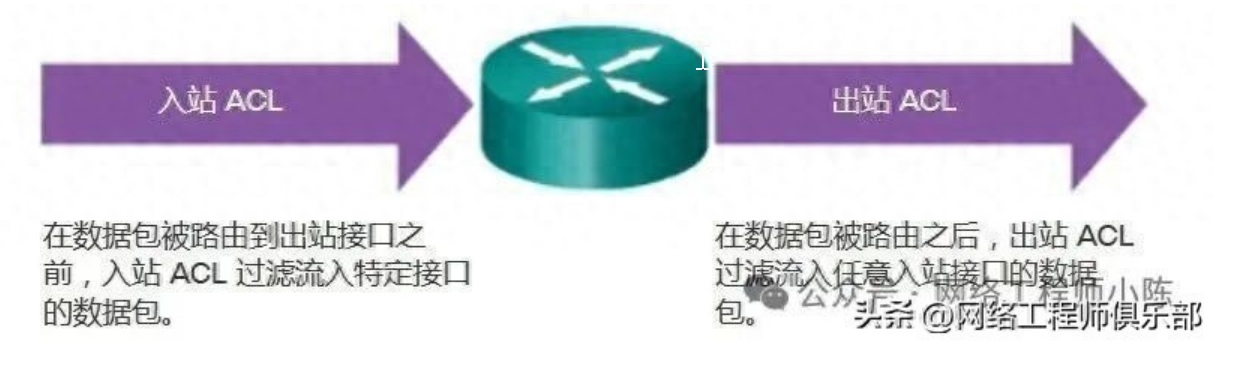
刚配完ACL,整个VLAN的用户全上不了网!” “明明只拦一个IP,结果全网瘫痪……” 访问控制列表(ACL)是咱们工作中控制流量、保障安全的利器。 但它的“威力”也意味着高风险—— 一条规则写错,就可能引发全网访问中断。 尤其在汇聚层或核心层部署ACL时,影响范围广,恢复
2026-02-13
一、理解文件 1.1、文件的概念 文件存储在磁盘上。(狭义) Linux中一切皆文件,即把所有需要交互的资源全部抽象成为文件:普通文件,目录文件,设备文件,管道文件...。(广义) 1.2、文件的认知 文件 = 内容 + 属性。 内容:文件存储的数据,如文本中的文字,程序二进
2026-02-12
要在独立 Tomcat 中实现「配置统一加载」,核心目标是让分散在不同位置(外部文件、配置中心、Tomcat 内置变量)的配置,通过一套统一的机制加载到应用中,避免每个应用重复写配置读取逻辑、确保配置来源唯一、更新方式统一。以下是分阶段的落地方案,从基础的文件统一加载到企业级的配置中心统一加载,适配
2026-02-12
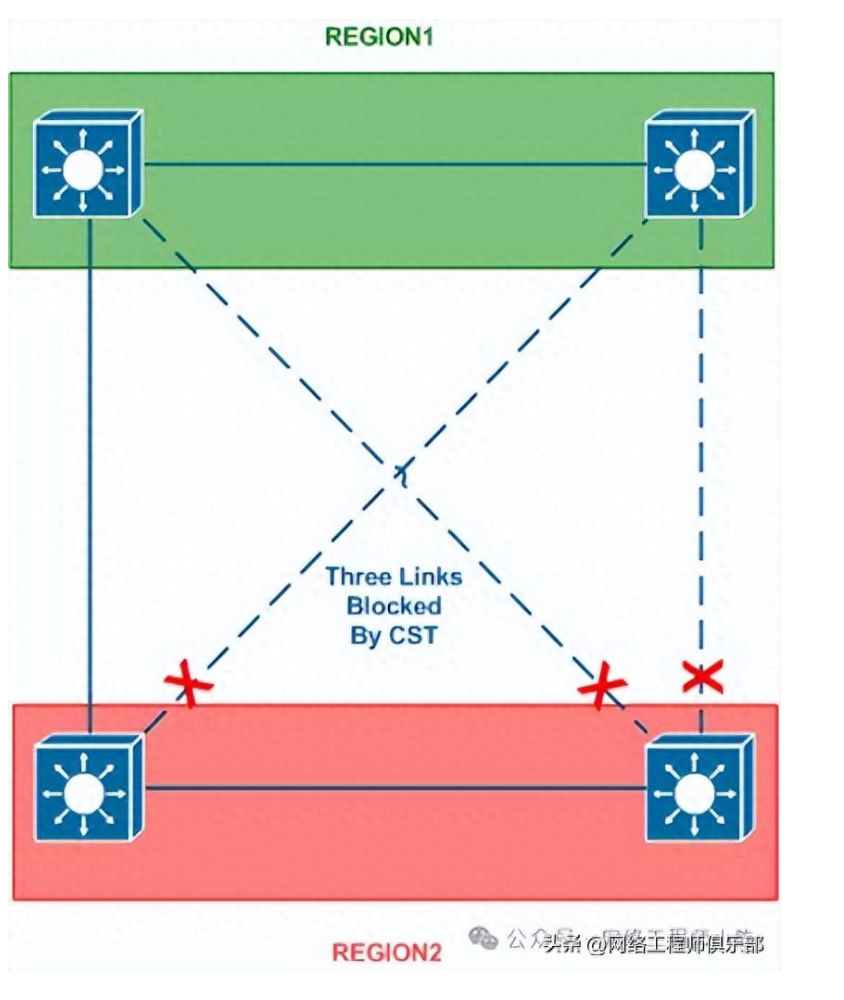
在企业网络中,交换机看似“傻瓜转发”,实则暗藏玄机。一旦出问题,往往表现为局部断网、速度慢、间歇性丢包,定位起来非常棘手。 但高手排错,从不盲目重启。他们有一套标准化的排查流程,称之为: 交换机排错四件套—— 查日志、看CPU、读ARP、验MAC 这四个动作,能在5分钟内锁定80%
2026-02-12
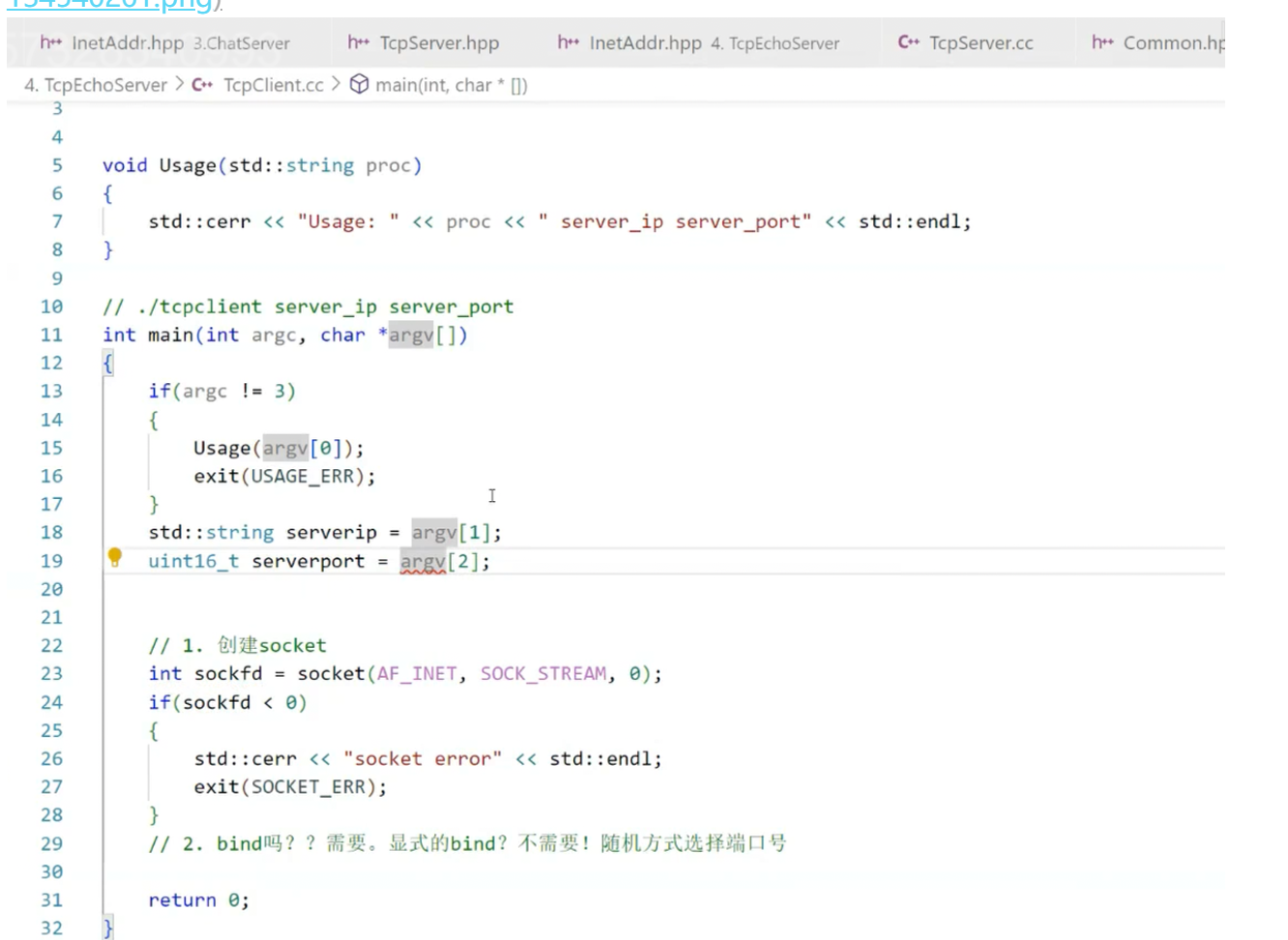
作为后端开发的核心技能,Linux 下的 TCP 服务器开发是绕不开的知识点。本文将从基础的 socket 编程入手,一步步实现 echo 服务器,并通过多进程、多线程、线程池优化并发能力,最后扩展到远程命令执行场景并补充安全防护方案,全程以实战代码和核心问题为核心展开。 一、基础篇:实现一个
2026-02-11
想要在独立 Tomcat 中实现「配置解耦」,核心目标是把 Tomcat 核心配置(server.xml/context.xml)、应用配置(web.xml)、业务配置拆分开,让可变配置(如数据库链接、限流规则、IP 封禁)独立管理,做到「修改不影响核心配置、更新无需重启 Tomcat、集群统一管控
2026-02-11

01 先搞清:UP 到底代表什么? 接口状态 UP 的含义: 物理层:线缆连接正常,光/电信号正常 数据链路层:两端协商成功(速率、双工) ≠ 网络层及以上通! ✅ UP 只说明“物理链路”和“二层”基本正常 ❌ 不代表IP能通、服务能访问 类比: 像公路
2026-02-11