MySQL中间件之ProxySQL(10):读写分离方法论
1.不同类型的读写分离
数据库中间件最基本的功能就是实现读写分离,ProxySQL当然也支持。而且ProxySQL支持的路由规则非常灵活,不仅可以实现最简单的读写分离,还可以将读/写都分散到多个不同的组,以及实现分库sharding(分表sharding的规则比较难写,但也能实现)。
本文只描述通过规则制定的语句级读写分离,不讨论通过 ip/port, client, username, schemaname 实现的读写分离。
下面描述了ProxySQL能实现的常见读写分离类型。
1.1 最简单的读写分离
如图。
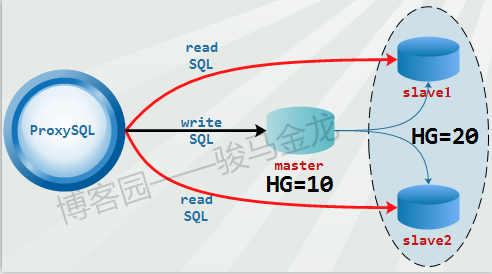
这种模式的读写分离,严格区分后端的master和slave节点,且slave节点必须设置选项read_only=1。在ProxySQL上,分两个组,一个写组HG=10,一个读组HG=20。同时在ProxySQL上开启monitor模块的read_only监控功能,让ProxySQL根据监控到的read_only值来自动调整节点放在HG=10(master会放进这个组)还是HG=20(slave会放进这个组)。
这种模式的读写分离是最简单的,只需在mysql_users表中设置用户的默认路由组为写组HG=10,并在mysql_query_rules中加上两条简单的规则(一个select for update,一个select)即可。
例如,下面实现的就是这种读写分离模式。
mysql_replication_hostgroups:
+------------------+------------------+----------+
| writer_hostgroup | reader_hostgroup | comment |
+------------------+------------------+----------+
| 10 | 20 | cluster1 |
+------------------+------------------+----------+
mysql_servers:
+--------------+----------+------+--------+--------+
| hostgroup_id | hostname | port | status | weight |
+--------------+----------+------+--------+--------+
| 10 | master | 3306 | ONLINE | 1 |
| 20 | slave1 | 3306 | ONLINE | 1 |
| 20 | slave2 | 3306 | ONLINE | 1 |
+--------------+----------+------+--------+--------+
mysql_users:
+----------+-------------------+
| username | default_hostgroup |
+----------+-------------------+
| root | 10 |
+----------+-------------------+
mysql_query_rules:
+---------+-----------------------+----------------------+
| rule_id | destination_hostgroup | match_digest |
+---------+-----------------------+----------------------+
| 1 | 10 | ^SELECT.*FOR UPDATE$ |
| 2 | 20 | ^SELECT |
+---------+-----------------------+----------------------+
这种读写分离模式,在环境较小时能满足绝大多数需求。但是需求复杂、环境较大时,这种模式就太过死板,因为一切都是monitor模块控制的。
1.2 多个读组或写组的分离模式
前面那种读写分离模式,是通过monitor模块监控read_only来调整的,所以每一个后端集群必须只能分为一个写组,一个读组。
但如果想要区分不同的select,并将不同的select路由到不同的节点上。例如有些查询语句的开销非常大,想让它们独占一个节点/组,其它查询共享一个节点/组,怎么实现?
例如,下面这种模式。
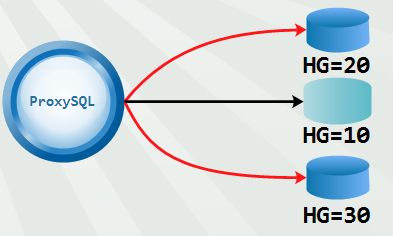
看上去非常简单。但是却能适应各种需求。例如,后端做了分库,对某库的查询要路由到特定的主机组(后文专门分析这种情况)。
至于各个组机组是同一个主从集群(下图左边),还是互相独立的主从集群环境(下图右边),要看具体的需求,不过这种读写分离模式都能应付。
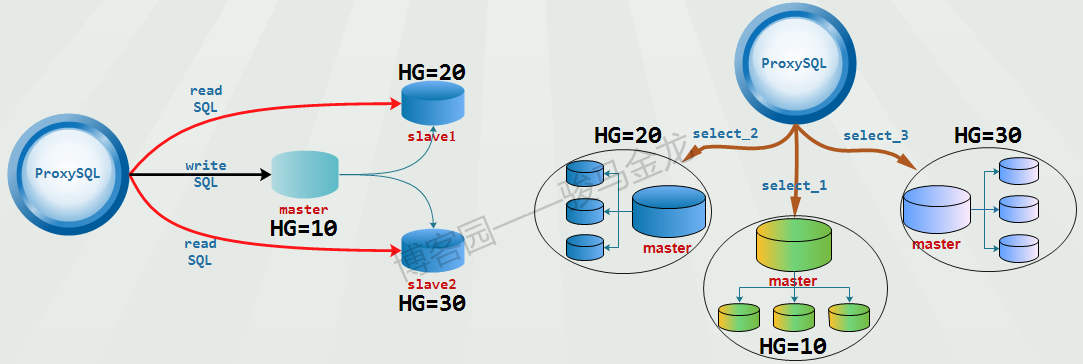
在实现这种模式时,前提是不能开启monitor模块的read_only监控功能,也不要设置 mysql_replication_hostgroup 表。
例如,下面的配置实现的是上图左边的结构:写请求路由给HG=10,对test1库的select语句路由给HG=20,其它select路由给HG=30。
mysql_servers:
+--------------+----------+------+--------+--------+
| hostgroup_id | hostname | port | status | weight |
+--------------+----------+------+--------+--------+
| 10 | host1 | 3306 | ONLINE | 1 |
| 20 | host2 | 3306 | ONLINE | 1 |
| 30 | host3 | 3306 | ONLINE | 1 |
+--------------+----------+------+--------+--------+
mysql_users:
+----------+-------------------+
| username | default_hostgroup |
+----------+-------------------+
| root | 10 |
+----------+-------------------+
mysql_query_rules:
+---------+-----------------------+----------------------+
| rule_id | destination_hostgroup | match_digest |
+---------+-----------------------+----------------------+
| 1 | 10 | ^SELECT.*FOR UPDATE$ |
| 2 | 20 | ^SELECT.*test1\..* |
| 3 | 30 | ^SELECT |
+---------+-----------------------+----------------------+
1.3 sharding后的读写分离
ProxySQL对sharding的支持比较弱,要写sharding的路由规则真心觉得有点繁琐。但无论如何,ProxySQL通过定制路由规则是能实现简单的sharding的。这也算是读写分离的一种情况。
如下图,将课程所在库分为三个库:"MySQL"、"python"和"Linux"。当查询条件中的筛选条件是MySQL时,就路由给MySQL库所在的主机组HG=20,筛选条件是Python时,就路由给HG=10,同理HG=30。
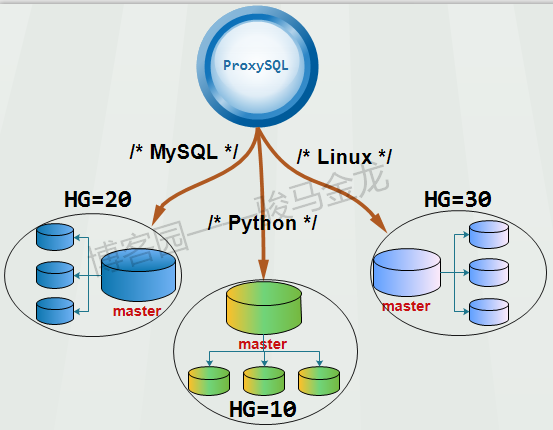
关于ProxySQL如何实现sharding的具体细节,我后面的文章会介绍。
2.找出需要特殊对待的SQL语句
有些SQL语句执行次数较多、性能开销较大、执行时间较长等等,这几类语句都需要特殊对待。例如,将它们路由到独立的节点/主机组,或者为它们开启缓存功能。
详细内容参见官方手册里的一篇文章,我已经把它翻译过了:ProxySQL Read Write Split (HOWTO)。
本文通过sysbench来模拟,以便为官方手册里的这篇文章提供测试环境。当然,如果您会sysbench或其它性能测试工具,可无视。
1.首先创建测试数据库sbtest。这里我直接连接到后端的MySQL节点创建库和表。
mysqladmin -h192.168.100.22 -uroot -pP@ssword1! -P3306 create sbtest;
2.准备测试表,假设以2张表为例,每个表中10W行数据。填充完后,两张表表名为sbtest1和sbtest2。
SYSBENCH=/usr/share/sysbench/
sysbench --mysql-host=192.168.100.22 \
--mysql-port=3306 \
--mysql-user=root \
--mysql-password=P@ssword1! \
$SYSBENCH/oltp_common.lua \
--tables=1 \
--table_size=100000 \
prepare
3.sysbench连接到ProxySQL,做只读测试。注意下面的选项--db-ps-mode必须设置为disable,表示禁止ProxySQL使用prepare statement,目前ProxySQL还不支持对prepare语句的缓存。不过ProxySQL作者已经将此功能提上日程了。
sysbench --threads=4 \
--time=20 \
--report-interval=5 \
--mysql-host=127.0.0.1 \
--mysql-port=6033 \
--mysql-user=root \
--mysql-password=P@ssword1! \
--db-ps-mode=disable \
$SYSBENCH/oltp_read_only.lua \
--skip_trx=on \
--tables=1 \
--table_size=100000 \
run
由于这时候还没有设置sysbench的测试语句的路由,所以它们全都会路由到同一个主机组,例如默认的组。
4.查看stats_mysql_query_digest表,按照各种测试指标条件进行排序,例如按照总执行时间字段sum_time降序以便找出最耗时的语句,按照count_star降序排序找出执行次数最多的语句,还可以按照平均执行时间降序等等。请参照上面列出的官方手册文章。
例如,此处按照sum_time降序排序:
Admin> SELECT count_star,sum_time,digest,digest_text
FROM stats_mysql_query_digest
ORDER BY sum_time DESC
LIMIT 4;
+------------+----------+--------------------+---------------------------------------------+
| count_star | sum_time | digest | digest_text |
+------------+----------+--------------------+---------------------------------------------+
| 72490 | 17732590 | 0x13781C1DBF001A0C | SELECT c FROM sbtest1 WHERE id=? |
| 7249 | 9629225 | 0x704822A0F7D3CD60 | SELECT DISTINCT c FROM sbtest1 XXXXXXXXXXXX |
| 7249 | 6650716 | 0xADF3DDF2877EEAAF | SELECT c FROM sbtest1 WHERE id XXXXXXXXXXXX |
| 7249 | 3235986 | 0x7DD56217AF7A5197 | SELECT c FROM sbtest1 WHERE id yyyyyyyyyyyy |
+------------+----------+--------------------+---------------------------------------------+
5.对那些开销大的语句,制定独立的路由规则,并决定是否开启查询缓存以及缓存过期时长。
6.写好规则后进行测试。
转载请注明出处:https://www.cnblogs.com/f-ck-need-u/p/9318558.html