锐捷S57H交换机直连ping不通
一、故障现象
设备上行直连ping 172.31.12.253 不通。部分视频业务转发卡断异常。前后未做配置以及网络拓扑变更、影响业务。 网络拓扑如下:
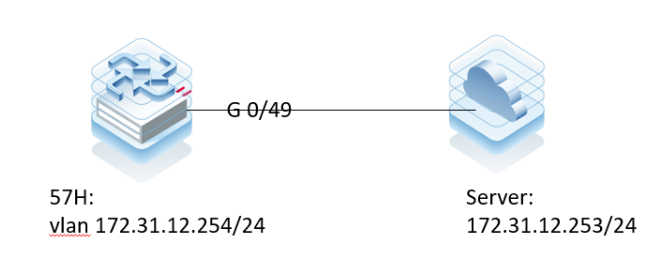
二、设备型号和版本
设备型号:5750H
设备版本:B12P8
三、故障排查步骤
1、 了解交换机直连不通的丢包点在哪里(可以使用ACL计数初步定位)
2、 确定交换机本身存在异常时控制面报文发包情况可以通过快转判断是否正常
3、了解整体端口发包机制:功能组件---》快转---》pkt---》端口
4、根据收集的信息和抓包分析出故障原因
四、故障排查过程
通过现场的信息分析,初步定位客户业务场景超出了设备性能
详细分析如下:
l 设备debug看ping 报文送到快转控制面延迟了30多秒。
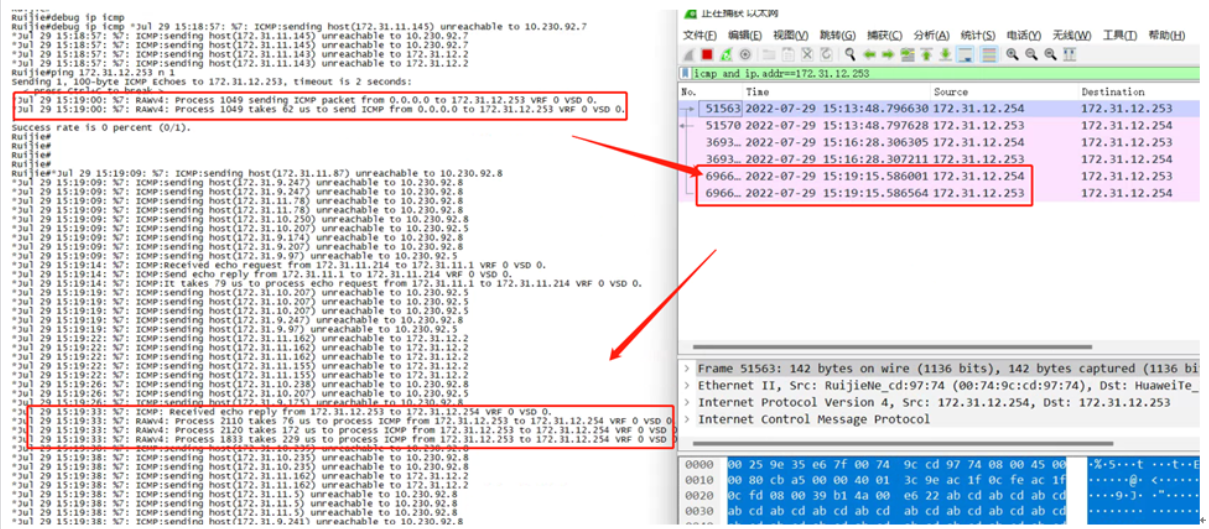
l 快转发包虚线程慢,发现EFMP-1中libpkt_sock_thread占用cpu高。
PI这边进展: 现象原因:从快转发包来看,协议栈将icmp报文 发送给快转后,快转发包虚线程要15s后才进行发包(从log上看)。快转发包虚线程是跑在CPU核1核上。CPU1核是转发核,目前看只有EFMP-1和libpkt_sock_thread CPU高。 怀疑点: 进行EFMP-1这个快转转发核上gdb,发现都是卡在HZ接口,内部调用sysconf这个libc库中的系统调用,但是就算是使用该系统调用,理论上也不会卡住这么久。目前看也只有分片重组定时器使用HZ这个接口,现场需要看下是否有大量分片报文。

l 快转的报文构造的分段了,分成3段才发往驱动,说明设备收到分片报文。
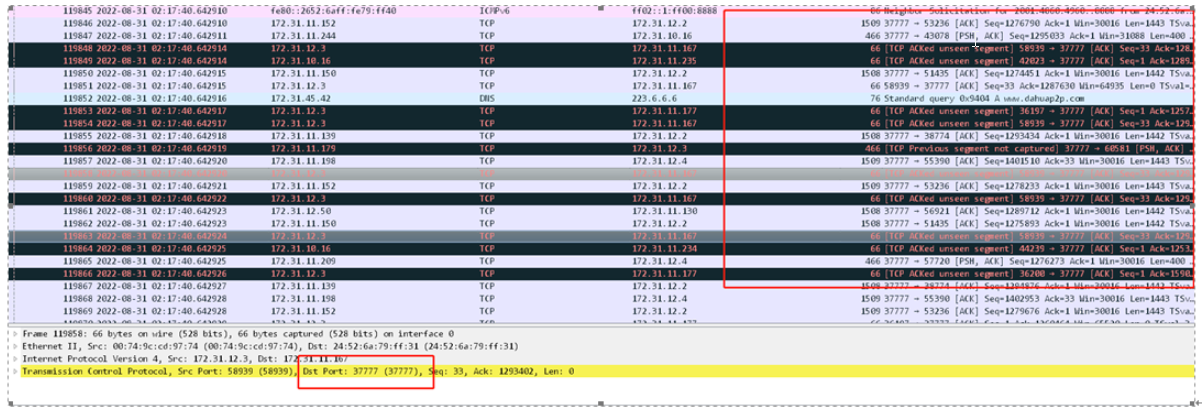
l 实际抓包查看现网中存在大量的分片报文,并且有很多分片报文丢包,导致CPU收不到分片报文,导致在等大包的组包,因此造成CPU高。
为什么大包送CPU慢?

l 从客户现场的信息看、部分报文速率较大,已经达到了NFPP的攻击水线,部分报文已经被隔离,导致送CPU不完整。
l 关闭NFPP后故障依旧。

l 查看芯片报文不能送CPU的原因,芯片存在MMU丢包,就是送CPU的报文太多了。缓存不够用造成部分送CPU的报文丢包。
l 改成MMU burst 模式,增加MMU 后故障依旧,此时可以确认客户业务基本超出了设备的性能。
进一步分析客户场景为什么会有这么大业务送CPU。
l 从之前debug和抓包的信息可以看主要是端口号37777的业务,可以确认这是大华的视频业务。这些业务都是高清的大包视频流。
l 查看设备的ARP可以看到部分设备的ARP处于incomplete状态,那么流量就处于未知名单播状态,这种情况业务流量需要送CPU转发。
l 由于客户的业务流量是属于大包视频流,速率较大,会比较容易消耗CPU的MMU,就会造成报文送CPU困难。会导致部分ARP没法即使更新而老化。
l ARP老化又会导致更多的业务变成未知名单播,从而跟多的业务送CPU导致恶性循环。
其他影响因素:
对于客户supervlan的场景,下面部署了2000个subvlan。这种场景存在arp泛洪,需要把arp泛洪到各个子vlan,当终数量增加,arp 更新就会增加CPU的压力。
总结:
直接原因是控制面等大包组播,CPU高。
根本原因:
客户supervlan的场景,
1、arp 更新比较耗CPU
2、终端数量增加,同一时间老化数量增加,导致大量未知名单播大包送CPU,超过MMU性能,造成送CPU困难。
五、解决方案
1、 针对现场组网优化方案为:
① 可以尝试将终端绑定成静态ARP,这样就不存在大量的ARP更新和未知名单播送CPU转发的情况。缺点:终端变迁的时候需要更新ARP。
② 可以降低subvlan的数量,推荐数量在100个以内,避免arp泛洪。
2、 针对性能不足彻底方案为替换高性能的交换机实现功能(例如框式交换机)
阅读剩余
版权声明:
作者:SE_You
链接:https://www.cnesa.cn/2580.html
文章版权归作者所有,未经允许请勿转载。
THE END